Seaway作品测试RTX3090显卡测评
RTX3090 性能极致炸裂的超级怪兽
嗨,大家好,我是Seaway,我们又见面了,再次受到BlenderCN社区邀请让我来测评本年度的超级核弹RTX3090。
前提声明
我不是显卡专业人士,也不是科学家更不是数学家,我只是一个民间草根,以下测评的数据只是基于自己的作品测试而得。一些非常细微的感觉,我无法通过具体专业的数据描述,只能使用一些形容词来表述,还望见谅。
还是和上次测试RTX2080一样,测试的方向是RTX3090在3D艺术创作中的生产能力。以下的测评虽然场景文件都是极端的设置,但渲染参数方面我并没有一味的开高某个参数,来得到一些不实际的测试结果,因为我的测试是基于自己实际创作流程为基准,是要把它运用到自己实际创作中的。
RTX3090为谁而战
在2013年NVIDIA推出了泰坦显卡,主要运用于人工智能以及深度学习研究人员和开发人员,这些创造性的应用需要泰坦显卡提供的额外更多的显存,以满足高端创意所需的大显存需求,NVIDIA在听取反馈意见后,为我们带来了RTX3090。
RTX3090是为高性能的内容创作、高负荷的数据科学研究,想要体验8K游戏的人们量身定制。无论是专业数字艺术家还是追求极致品质游戏和视频创作的爱好者,RTX3090都能为你提供强大、稳定、高效的核弹级性能。
在创作领域RTX3090具有24GB快速GDDR6X的超大显存,为你追求极致性能,用于大型模型、详细场景和高分辨率纹理的艺术创作保驾护航。在专业图像软件运用中RTX 3090提供的性能比RTX 2080 Ti和TITAN RTX高出33%-105%。而且由于RTX 3090具有24 GB的超大显存,它可以处理的数据集的大小是RTX 3080的两倍。并且RTX3090仍然支持NVLink,这让你可以挂接更多RTX3090来进一步提升更强劲的性能。
另外,作为全球首款8K HDR游戏GPU,RTX 3090支持你在绚丽的8K HDR中进行游戏、捕捉和观看游戏,拥有用于8K游戏的全新DLSS超性能模式(DLSS Ultra Performance)、配备可单线连接8K电视的HDMI 2.1、支持能够进行8K HDR游戏捕捉的GeForce Experience,以及用于高效播放8K HDR流媒体视频的AV1解码。RTX 30系列GPU是首批支持硬件加速的AV1解码以实现流畅8K 60 FPS播放的GPU,与现有的H.264、H.265(HEVC)、VP9解码器相比,效率更高。AV1将播放高分辨率视频所需的带宽降低了多达50%,使其成为下一代4K和8K HDR Youtube视频的理想选择。
NVIDIA Studio 驱动
你可能会奇怪,我为何在这里要说驱动? 硬件之上需要软件适配,硬件的功能得以施展必须配备最优化的驱动,不然硬件虽然参数强大,但是实际上跑起来坑太多,根本没法投入生产,那时候后悔就晚了,不过有了NVIDIA的studio驱动就完全不担心这些问题。
NVIDIA在今年8月推出了NVIDIA Studio 驱动,此驱动程序专为创作者构建,它服务于数字艺术创作软件,包括Adobe Premiere Rush、Premiere Pro、Blender Cycles、V-Ray 5 for Maya、Flicker Free和BorisFX Optics等等。所以,你使用RTX显卡(包括GTX10系列)作为生产力硬件的话,强烈推荐安装NVIDIA Studio 驱动,这样你的显卡会以最佳性能为你服务。
可以访问这里了解更多详细内容:https://www.blendercn.org/9659.html
*至于使用RTX显卡的Blender用户就更加-必须–马上更新了,因为NVIDIAOptiX渲染引擎与Blender的Cycles紧密联系在一起,
这会让Cycles享受到RTX强大的加速buff,RT Core加速光线追踪和Tensor Core加速的AI降噪功能。
*使用RTX30系列的小伙伴请务必更新最新的10 月 Studio 驱动。不然Cycles的动态模糊无法使用OptiX加速。RTX30系列显卡也无法提供最佳性能。
注意!顺序可别搞错了,先安装RTX显卡,然后再安装NVIDIA Studio 驱动。
可以通过 GeForce Experience或 NVIDIA 驱动下载页面下载最新的10月 Studio 驱动 (456.71)。
测试平台:
测试软件:Blender 2.90 正式版 (对比RTX2080会比较公平。)
测试主机:(由BlenderCN社区 裴雪珂老师提供)
显卡 Nvidia RTX3090 24GB (显卡驱动更新到官方推荐的 256.71)
AMD Ryzen 3900X CPU
96GB DDR4内存
BIOSTAR 512GB M.2硬盘
显示器X2 分辨率:1920X1080
操作系统:Win10 64位教育版
机箱:爱国者黑曼巴 F1 风冷散热
电源:750W
好,说完前面这些,我们正式开始本文。请出今天的主角RTX3090!

在收到显卡后我并没有急着测试,而是特意到官方查询了RTX3090的参数,把我关注的技术参数列在下面。
NVIDIA 架构:Ampere
GA102-300-A1核心
CUDA核心数量:82组SM单元共计10496个流处理器
第2代RT Core 82个 提供20Giga Rays/s
全新第3代Tensor Core 328个
显存配置:24 GB GDDR6X
显存位宽:384Bit
最高 GPU 温度:93℃
显卡功率:350w(电脑电源最低要求750W)
虽然我在没有拿到显卡前就梯子到油管上看了人家的测评,让自己心里有个准备,但是实际测试还是让我吃惊不小。
房间光线暗,手机拍照效果一般,小伙伴们凑合看吧,哈哈



哼哼~~~你们的新老婆在我手上!

再看看RTX20….突然~~~不!不!不!我不能喜新厌旧,我不能喜新厌旧,我绝对不是那种人~~~~~~
这次官方的造型设计,个人非常喜欢,整体造型非常酷,做工精细,非常有感觉。
当然这新老婆分量也很十足,大概有6公斤重!!!把它塞进机箱我折腾出一身的汗,哈哈。
再来两张微距细节


在散热方面我在这里就直接说自己测试后的感受了:( 注:全部测试都是机箱闭盖环境下完成,没有任何开盖的情况!)
昆明这几天阴雨,房间温度20摄氏度左右(看来天公作美,给予这显卡自然降温buff,哈哈)。
RTX3090使用了双风扇导流设计,一个在正面,一个在背面,并且在尾部(DP接口面)也有自己的散热口,这样能很好的给显卡散热,不光如此,还能对机箱整体内部做散热,在测试的这段时间中,RTX3090温度控制非常好,观察到最高温度77度,但也只是一瞬间,平均在68~74度之间,渲染速度没有非常明显的影响,这个比起RTX2080要优秀很多。
好,我们进入实际测评:
*以下测试全部为极端数据,且为个人作品测试数据和对比,故只作为娱乐参考,不能作为权威测评。
*测得的渲染时间我都按四舍五入的方式统计。
*注:与RTX2080做对比有些不公平,没办法只有RTX2080的测试数据,只好委屈下2080了,哈哈
关于渲染分布块大小与渲染速度:
我分别测试了256×256、512×512、1024×1024、2048×2048
最佳还是推荐512×512,1024块要慢几秒,256块和512差不多,但渲染画幅尺寸过大,256还是不-推-荐。
测评第一个作品:凯普巨人殖装胸像
关于凯普装甲文件在上篇RTX2080有详细介绍,这里就不再重复了,可以访问RTX2080测评了解。
https://www.bilibili.com/read/cv6952550
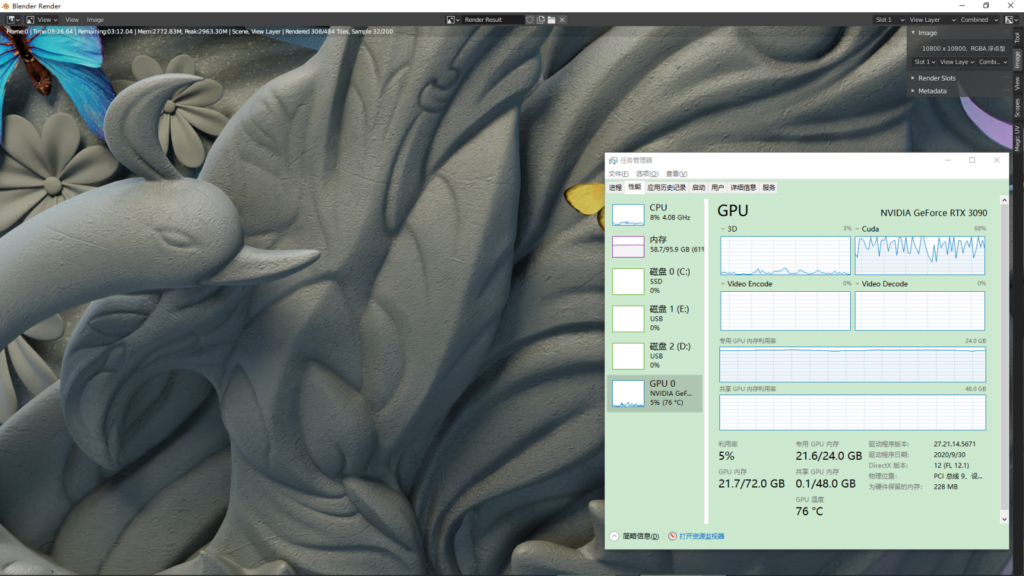
视口显示,雕刻细节全开9级,面数3600万,文件起始内存占用9.6G,显存占用4.9G
Blender2.90正式版,Cycles渲染器
采用块分布式渲染,块大小:512X512,开启OptiX 后期降噪:Color+Albedo+Normal
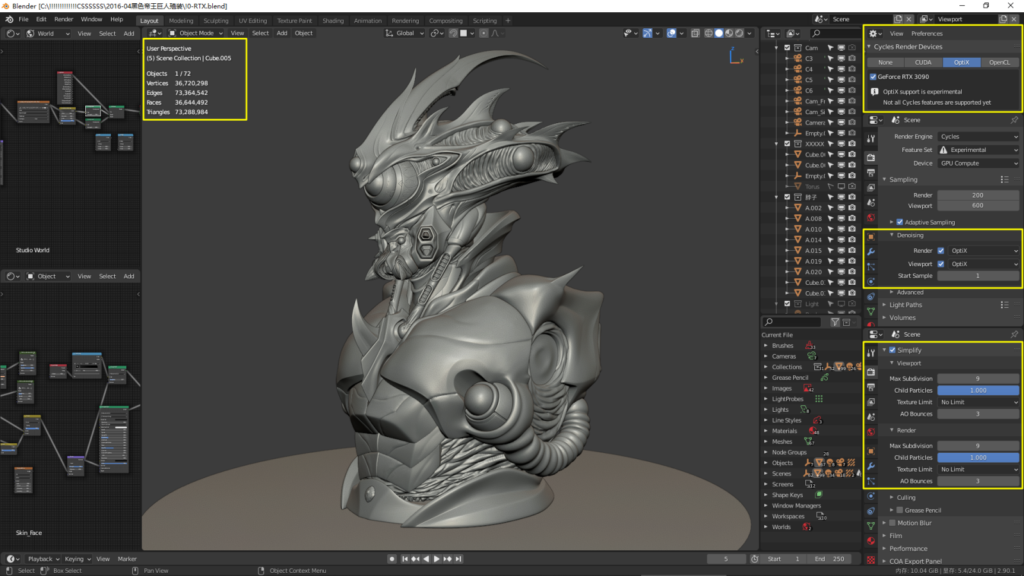
视口实时渲染:
首次Cycles渲染加载场景耗时1分20秒,3600万面数,大概0.5秒成像,2秒不到细节全出,4~5秒细节进一步精进,8秒基本已经完事了,后面就是按照你指定给Cycles的采样再更加精细而已。这个作品对于拥有24G显存的RTX3090来说轻松应对,在Cycles开启后,快速切换全屏,反应速度非常快,RTX2080要慢一些。具体可以看我后面的参数对比图。
推荐观看操作视频,这个最直观让你感受RTX3090的强大能力。
https://www.bilibili.com/video/BV1hZ4y1V7CV?p=1

100采样基本就是10秒,特意截这图,这就是10秒后的品质,已经非常棒了。
视口实时渲染的一个对比图
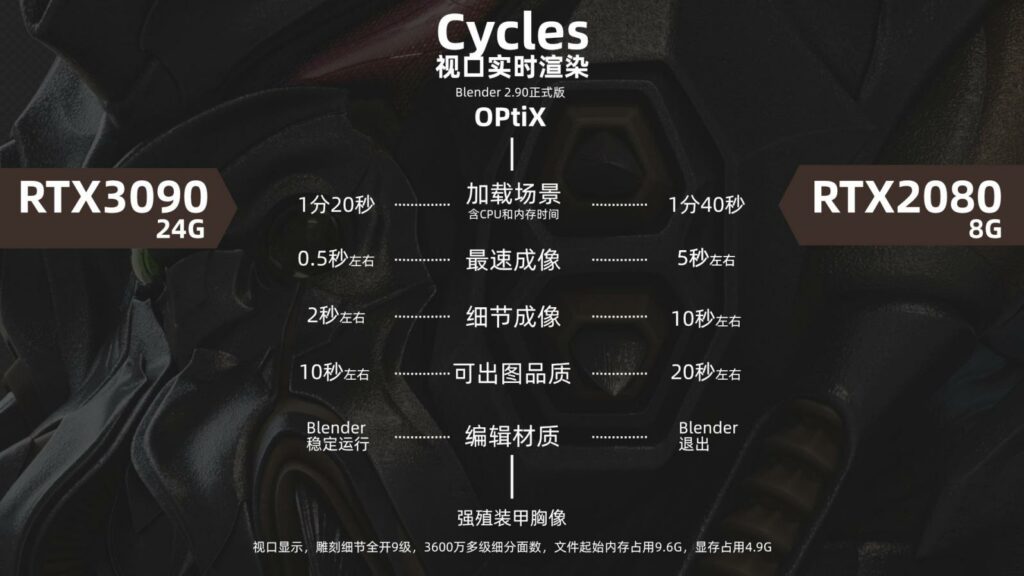
RTX3090 VS RTX2080 视口实时Cycles渲染
注:此测试时间只针对此案例,不同场景内容会相应加减时间。
EEVEE视口实时:
这个其实没有啥测试的必要,因为RTX2080就已经毫无压力了,RTX3090更是轻松应对。
加载不到1分钟,拖动视口和编辑Mesh都毫无压力,EEVEE视口实时能力我在后面准备了一个更加对胃口的案例,所以不在这多说。
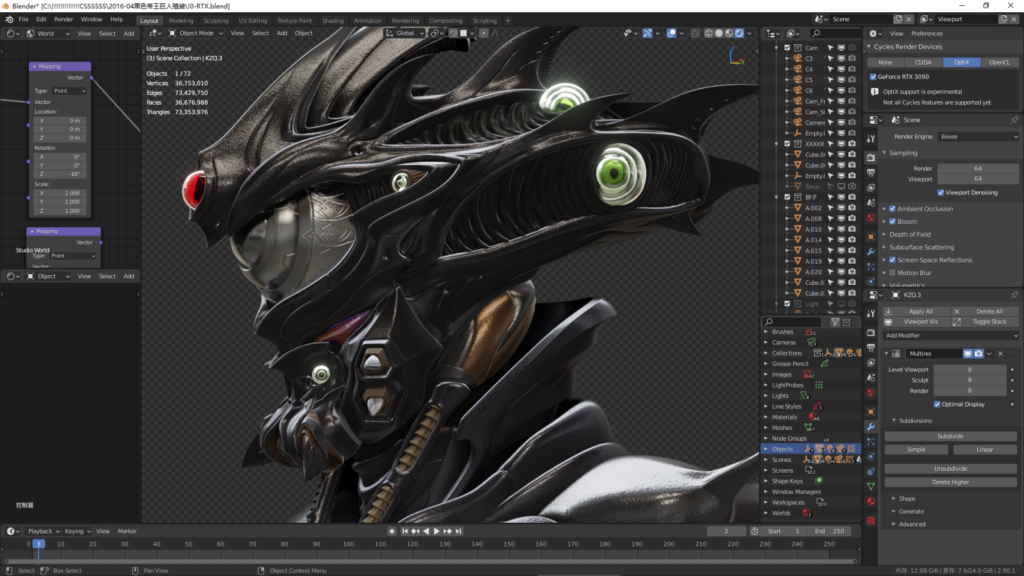
EEVEE最大的不足就是阴影和折射
接下来是重头戏,成品渲染测试:
这次我一上来就直接测试8K的,尺寸:8640X4800 170块 采样:200 渲染时间:6分13秒 (RTX2080渲染时间:47分25秒)
瓦特!6分13秒!!??你不信是吧,连我都不信,时间出来我都懵了,RTX2080用了47分钟,这家伙6分钟就完事啦!!??
于是我连续重渲了三遍,分别为:06分12秒、06分14秒、06分13秒。
测到这里,老实说心里真是有些激动,这渲染速度实在让人不要太舒服。
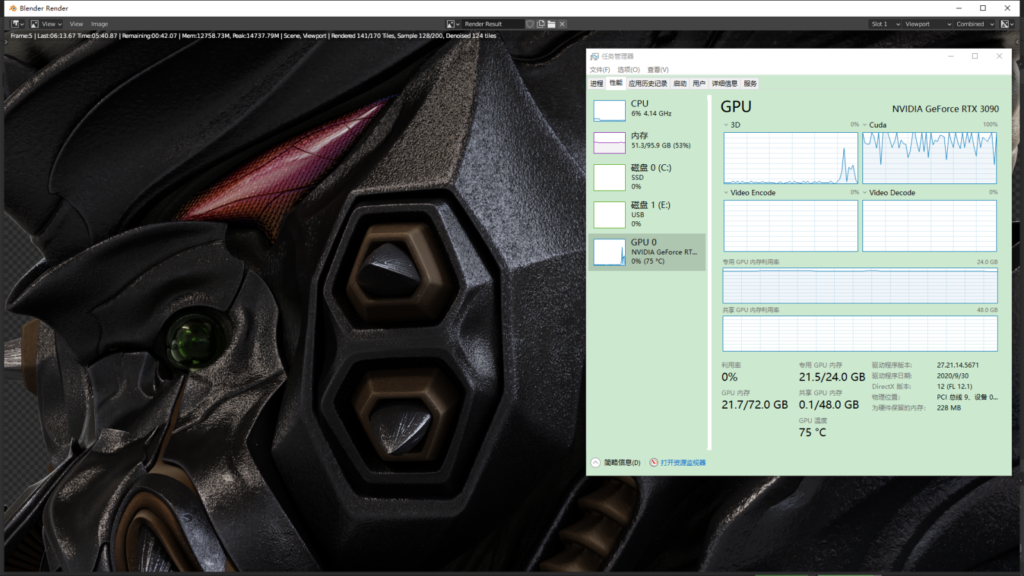
这里截取第四次渲染的过程(这四次是连续渲染),可以看到前面有一个06:14(四舍五入)的时间。
好,来看下其他几个尺寸的时间:
没有开启OptiX加速的CUDA渲染成图的时间:
图片尺寸:3600X2000 32块 采样:350 渲染时间:4分34秒 (RTX2080渲染时间:17分13秒)
开启OptiX加速渲染成图的时间:
图片尺寸:3600X2000 32块 采样:350 渲染时间:2分01秒 (RTX2080渲染时间:5分43秒)
图片尺寸:5040X2800 60块 采样:300 渲染时间:3分06秒 (RTX2080渲染时间:10分39秒)
别急,后面才是主菜:
10800X6000 264个分布块, 采样:200 渲染时间:9分35秒(RTX2080渲染时间:1小时42分09秒)
1万像素只需要9分半钟,渲染了3次,都是9分30秒~9分35秒。这个实在是太香了啦,哈哈
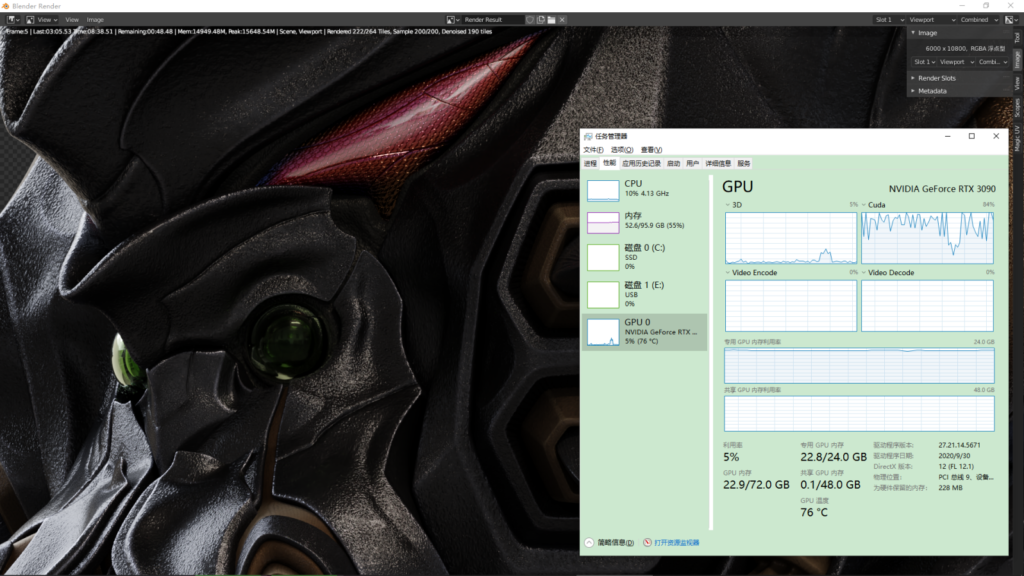


1万像素,1:1局部截图
来看看渲染时间对比图,没有对比就没有伤害,一下子RTX2080就真的不香啦,哈哈
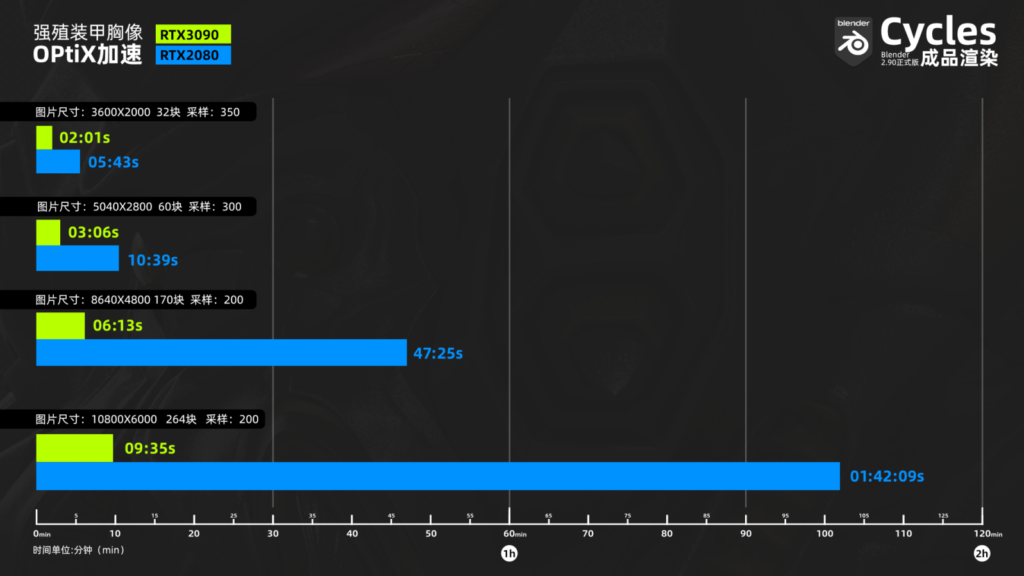
图为不专业的我花了一下午整出来的,不要扣细节,时间是真的,柱状图绝对有误差,看个明白就好。
测评第二个作品:春蝶入芳夏(素模版)
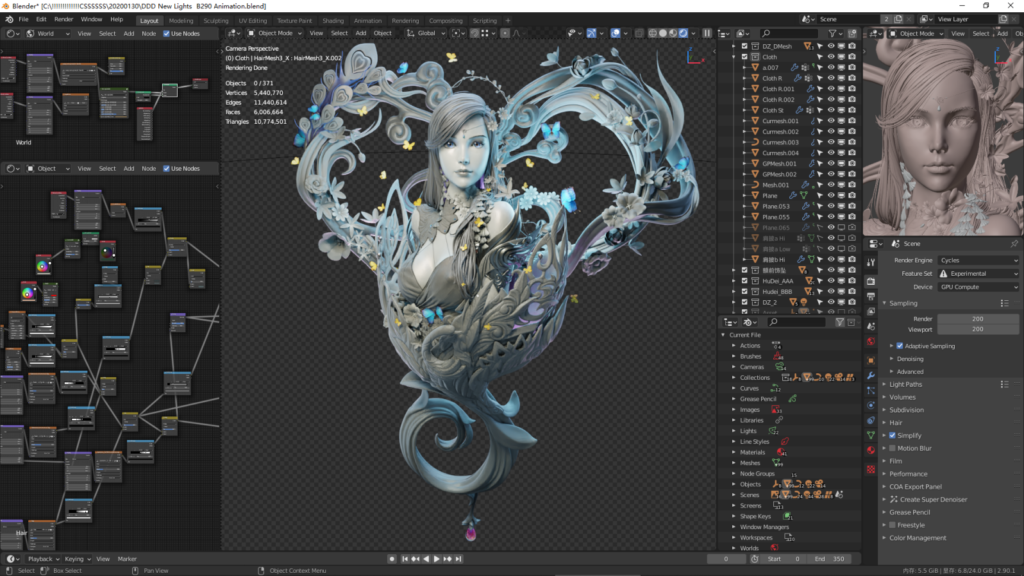
文件介绍:
灯光22个,一部分是动态雕刻,一部分是精雕后减面的模型,还有曲线模型总共300多个部件,600万面数,模型大部分是没有UVmap的,全部材质是用程序纹理和纹理贴图混合得到的材质,运用了大量的程序节点完成,还有运用了VertexColors。
这个案例侧重于Cycles成品渲染和动态模糊的测试。
先来看看成品渲染:
6480X6480 169个分布块 采样:300 渲染时间:5分38秒(RTX2080时间:14分09秒)(RTX2070s时间:41分57秒)
(注:这里的RTX2070s的渲染时间不是非常准确,渲染后期降频很严重,渲染时间过长,这里列出来也只是一个参考。)
8640X8640 289个分布块 采样:200 渲染时间:6分24秒
10800×10800 484个分布块 采样:200 渲染时间:13分02秒
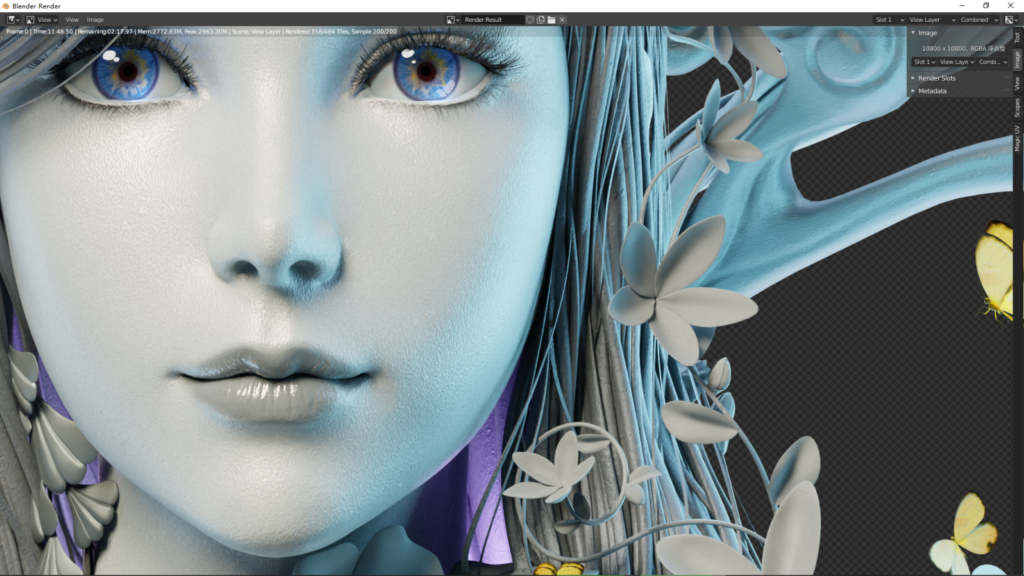
10K 1:1 局部截图,可以看到纹理的细节呈现非常好。( 注:面部材质细节为纯程序纹理节点组 )
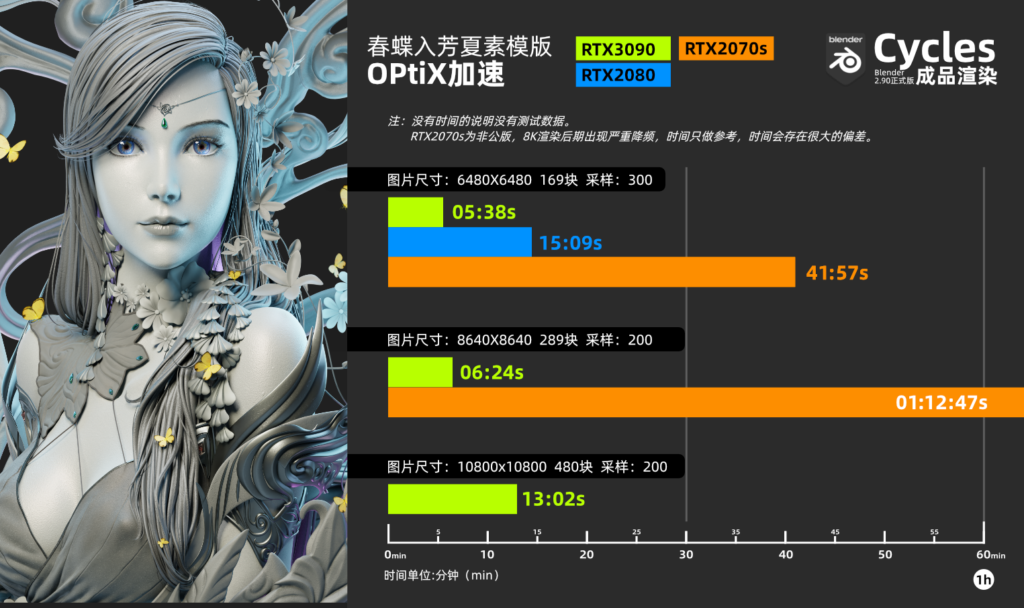
渲染时间对比
OptiX加速 Cycles 运动模糊:
这次显卡驱动更新中有一个重要的更新,就是OptiX对运动模糊渲染的支持。
这个能力不是只有30系列有,20系列也支持,快去更新显卡驱动吧。(GTX10系列不知道是否支持)
需要注意的是:
1运动模糊无法再视口中预览,必须成品渲染才可看到。
2 在首次渲染时,会出现一个编译过程【Loading render kernels (may take a few minutes the first time)】,耐心等待它的完成,之后你就可以在运动模糊渲染中使用OptiX加速了。
这里放上自己的动态模糊测试对比图。

可以看到,开启运动模糊和不开启在时间上差距不大,并且品质很好,这要比通过后期使用Vector通道得到的效果精确。
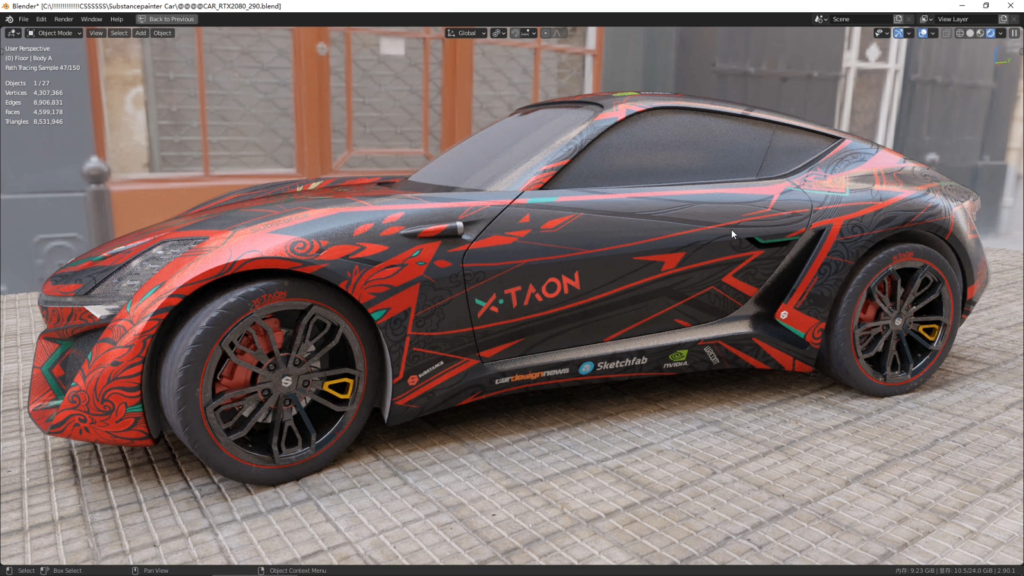
测评第三个作品:炽天使 跑车场景
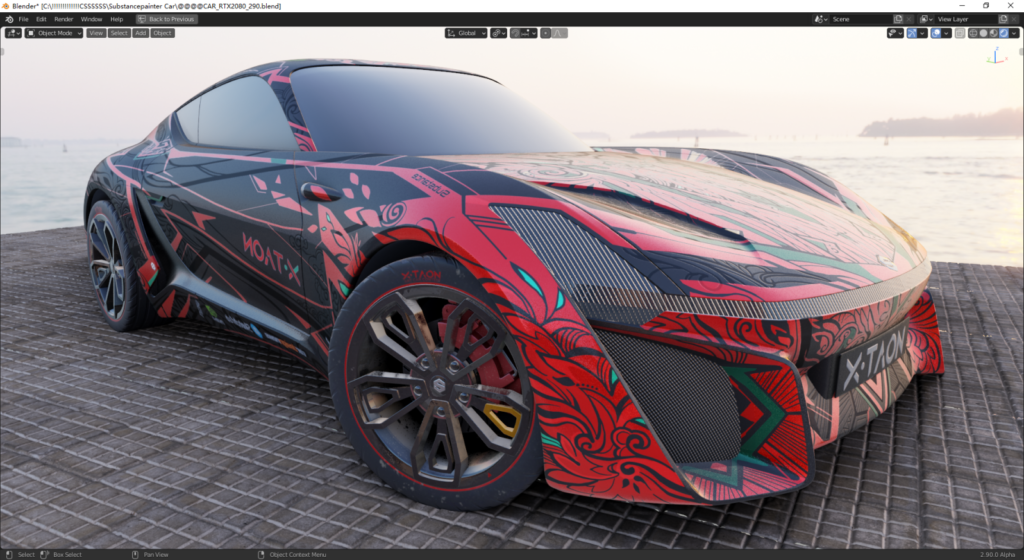
文件介绍:
原来参加Substance Painter比赛作品,拥有32张贴图,其中8K的有12张左右(具体记不清了,都是从Substance中输出的。)这个作品非常适合HDR环境照明下的实时光照渲染。这场景虽然对象不多,面数也不复杂,但地面是细分置换修改器得到的高精细地面,还有非常复杂的多张8KMask贴图混合而成的材质结构。
这场景在RTX2080上渲染前加载数据使用了1分34秒,然而在RTX3090下只需要41秒左右,差不多快了50多秒的时间。因为RTX3090的位宽是384bit的,对数据加载的速度要优于RTX2080许多。
好我们来看测试截图,(注:截图左上角文件名称带有RTX2080字样请无视,绝对没有造假)
Cycles的实时视口渲染:
HDR全环境光照效果,视口移动毫无压力,车体质感非常好。
这个在RTX2080就完全没有任何压力,RTX3090就更是轻松至极了。反应速度和成像速度都极为迅速。
在切换加载环境HDR贴图到成像的速度上,RTX3090要比RTX2080快一些,RTX2080大概在1秒,RTX3090大概在0.5秒。
还是推荐看视频演示吧,无法码字描述,原谅我墨水已干。(先声明:视频没有任何加速)
https://www.bilibili.com/video/BV1hZ4y1V7CV?p=2
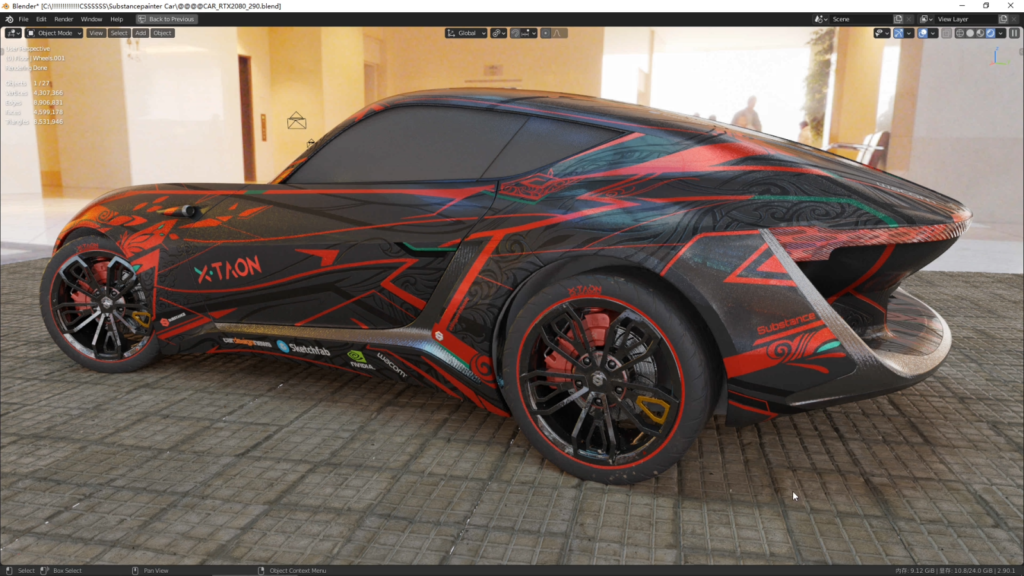
EEVEE视口实时显示:
场景加载和贴图加载只需要41秒左右,比RTX2080快很多,2080大概在1分15秒才能加载完成。
大家自己看视频吧,反正我也只能用牛!快!这些来形容,或者噼咔噼咔,咔嚓咔嚓(看不懂吧!异乡人!去找派蒙给你翻译下)
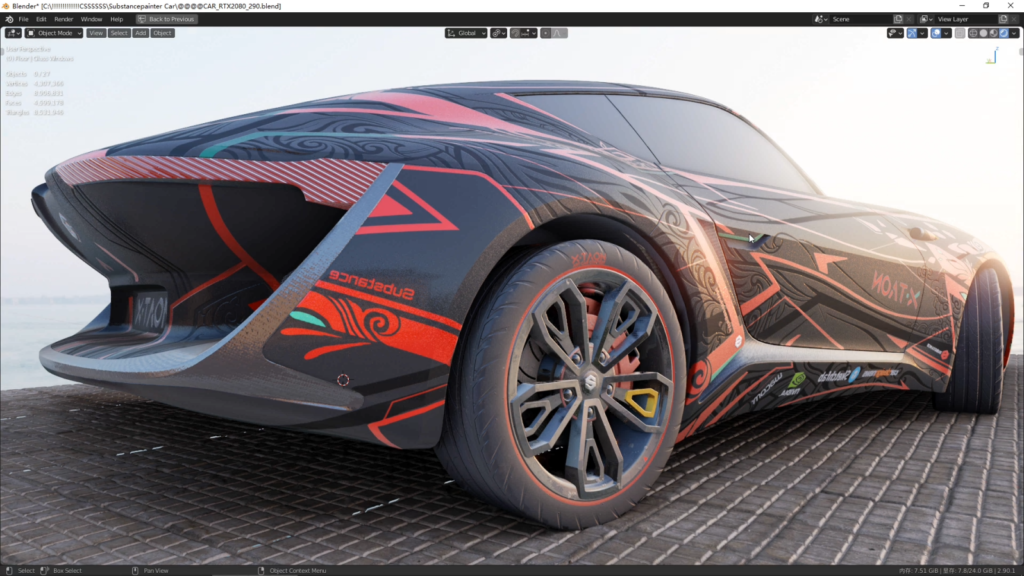
最后和小伙伴们分享下自己对Bender的EEVEE引擎和Cycles渲染器的一点看法:
EEVEE的优点不必说,这里说说我遇到的一个问题:
在模型很多,面数超高,材质节点结构也非常复杂的情况下,EEVEE视口更新是有明显延迟的,视图拖拽和材质编辑视口都会有明显的卡顿。一旦场景中材质和模型发生“结构编辑性”改变,它必须重新计算场景和材质,而根据场景对象和材质复杂程度,重新计算加载的时间也会变长(Cycles也会重新计算,但相比之下速度超快)。当然更新速度在RTX3090中有很明显的提升,但卡顿,延迟还是存在。所以EEVEE引擎适用于游戏级模型、单体复杂的模型展示和成套的PBR材质流程场景,一次完成加载,没有修改直接展示。而成品渲染方面,品质和速度面对拥有OptiX的Cycles来说几乎没有优势。(以上只是提出一种观点,希望EEVEE能更好的解决复杂情况的能力。现在EEVEE其实是没有得到显卡很好的加速支持的,不过也许在不远的未来…我很期待)。
再来看看现在的Cycles渲染器,精确的全局渲染,精准的光线追踪,细腻的光影,丰富的通道和matte,随着NVIDIA带来的RTX加速技术,Cycles最致命的缺陷“渲染慢”的短板彻底解决了,基本上成像预览都像开了挂一样秒出,所以如果你对画面有很高的要求,大场景,超高面数对象和复杂光影和材质编辑的话,Cycles+OptiX是你的最佳首选。当然不光是Cycles,Vray、Keyshot、OctaneRender等等也同样享受RTX的加速技术。
最最后分享几张截图结束我们这次的测评吧~~~~~
以下均为视口实时截图,猜猜看,他们是cycles还是EEVEE所为。
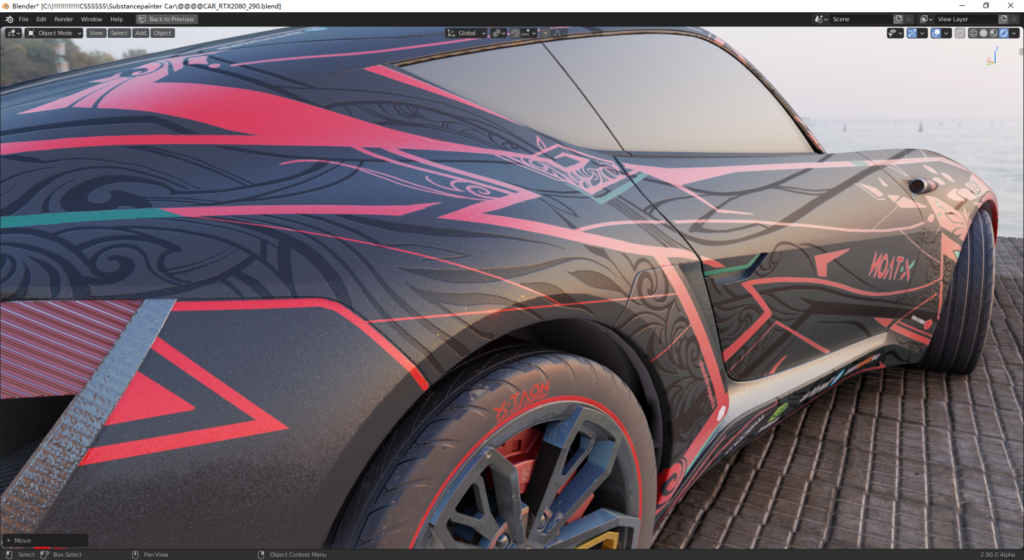

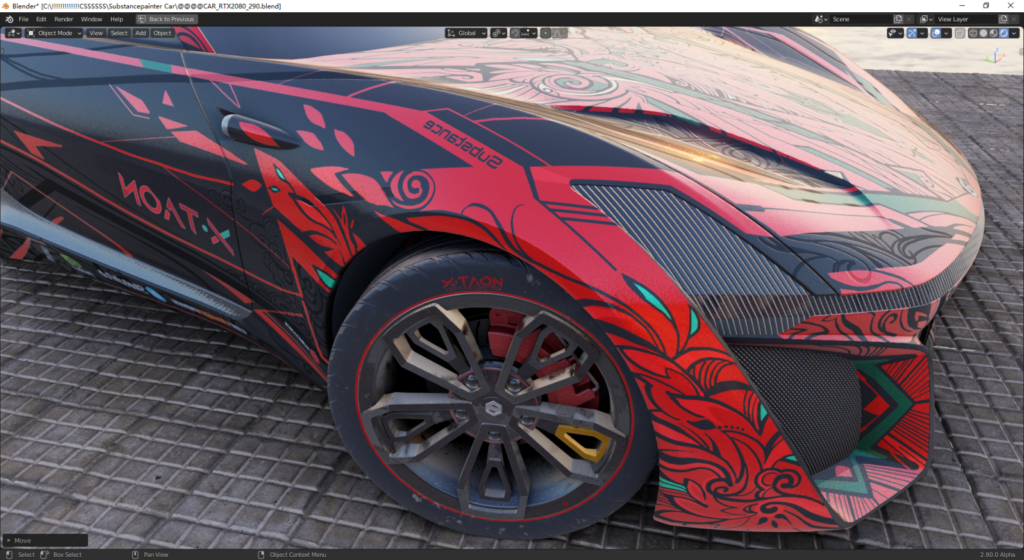
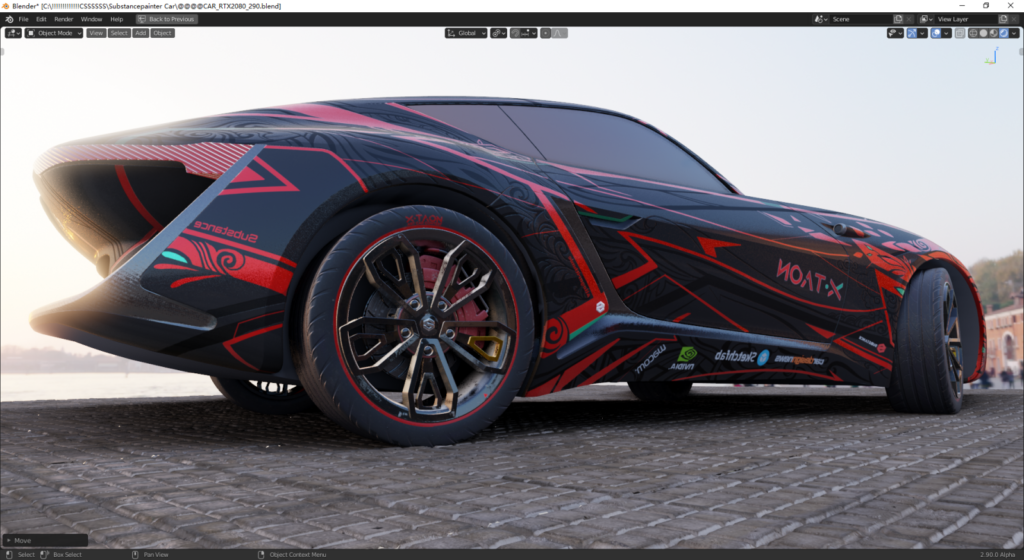
总结
RTX3090说实话已经非常接近自己心里的完美了,个人测试下来总的感觉就是稳定,快速高效,温度控制很好,而且渲染时风扇噪音也不大,24G大显存让RTX3090可以胜任超多对象面数的复杂场景,比如城市,森林,战场这些都能很好的发挥它强大的性能。对于Blender而言,RTX3090是一个极其强劲的战力伙伴,而这只是起点,因为NVIDIA和Blender基金会的合作仍然在继续,再未来将会带来更多惊喜。
如果说RTX2080是飞机的话,RTX3090就是火箭了,你想体验极致游戏的同时又想拥有超强的创造性能,那RTX3090是本年度最佳选择,它是极致游戏体验与超高效生产力完美并存的超级怪兽,无语伦比的性能实在无法用言语和文字来表达,RTX20系列完成了质的一次转变,而RTX30系列在此基础上又飞跃到了一个让人惊叹的高度。RTX30系列开启了一个全新图形生产阶段。无论在游戏娱乐,艺术创作,shader编写,逼真的视觉开发都带来了前所未有的效率和品质。所以,这不是一款普通的显卡,而是会带来革命性开启新纪元的超级怪兽。
朋友!
欢迎来到新数字视觉纪元
RTX3090


一万五啊 跪了跪了
3090生产力太强了。