原文链接:https://www.bilibili.com/read/cv6952550
嗨,大家好,我是Seaway,一个自由数字艺术创作者,非常高兴在BlenderCN社区发布我用RTX显卡的评测报告。
关于NVIDIA RTX 2080作为一个3D艺术创作者,我对于显卡专业术语和其中的复杂科技是不完全懂的,所以我的评测主要是围绕自己的作品在Blender中运用这款强劲的显卡实际表现为主,以我个人的视角来展示这块显卡在我的实际创作中带来了哪些与以往流程不同的感受。
————————–NVIDIA RTX2080 8G 开箱 ——————————



话不多说,塞进电脑,开始使用~~~~~~~

测试软件:Blender开发版2.9 Beta (2.83和2.9基本一致,为了节省时间就全部选择2.9版本测试)
测试环境:(由BlenderCN社区 裴雪珂老师提供)
显卡 Nvidia Geforce RTX2080 8GB
AMD Ryzen 3900X CPU
96GB DDR4内存
BIOSTAR 512GB M.2硬盘
显示器分辨率:1920X1080
操作系统:Win10 64位教育版
机箱:爱国者黑曼巴 F1 风冷散热
测试目的:
RTX显卡OptiX加速在高面数、多材质节点结构、多张高分辨率贴图下的Cycels视口预览速度和成品渲染速度和EEVEE实时渲染效率,材质编辑效率。
测试作品-強殖装甲胸像
测试渲染器:Blender2.9beta Cycles
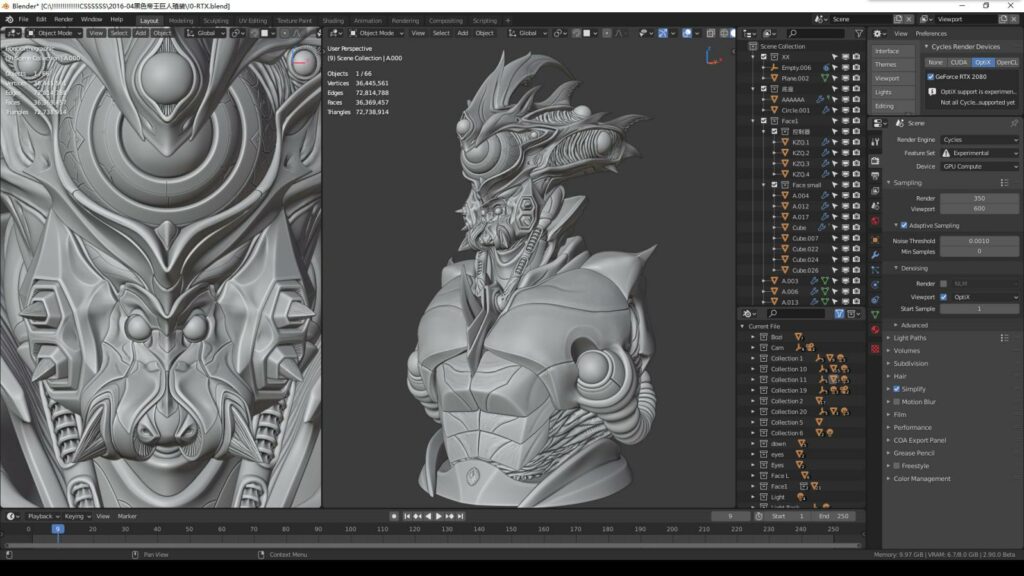
场景文件介绍:原有72个对象,在RTX2080下重新对部件进行编辑整合变成60个(多余的是灯光和虚拟物体),全部60个对象细分等级都在Blender视口环境(注意!是视口中,不是最终渲染)下开到最高,全部面数3600万左右,40张贴图,45个复杂节点材质重新编辑。
测试结果:(以下测试结果是极端条件数据!)
*视口渲染-2000万面数的场景进行Cycles,OptiX渲染(极端条件)
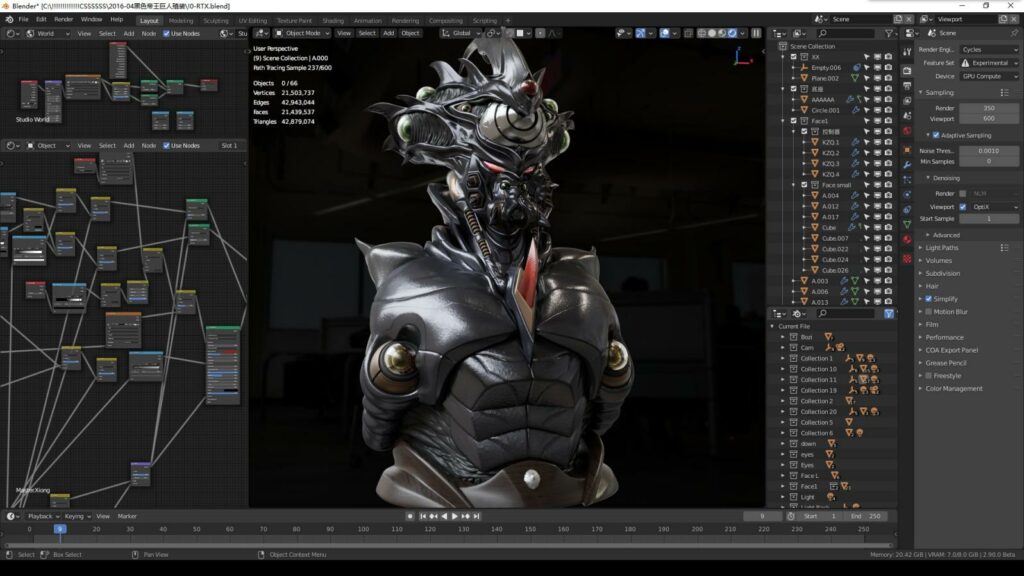
首次Cycles渲染加载场景耗时50秒,出现图像4秒就可以看到全部效果(包括凹凸细节也都很清楚),调整视口角度非常顺滑流畅,重渲染2秒已经很清晰,4秒后细节清晰,7~9秒后基本可以肉眼确认材质的整体,细节品质了。
测试结论:在2000万面数下可以轻松快速的编辑材质,毫无任何延迟和卡顿,视口渲染更新2秒就可看到材质改变后的结果。
*视口渲染-全部3600万面数的场景进行Cycles,OptiX渲染(超极端条件)
首次Cycles渲染加载场景耗时1分40秒,5秒出现图像后10秒就可以看到全部效果(包括凹凸细节也都很清楚),调整视口角度感觉到卡顿,重渲染5秒渲染已经很清晰,10秒后细节清晰。在3600万面数下编辑材质会导致Blender退出。
*视口渲染-总结
这个说实话,真的让我有些激动,RTX2080实在强悍!这对于3D艺术创作是一个强大的生产力工具。
视口渲染、预览材质和成品图像一直是我认为最烦躁的事,反复的调整和反复的等待,大量的时间都在等待中浪费掉,再强悍的CPU速度也不过如此,作品越是复杂精细,等待预览的时间也相对变得更加漫长,而现在RTX显卡让我改变了这个痛苦的困境,它让材质编辑和预览变成了我现在最最喜欢的环节,你可能觉得我这个太像广告词,哈哈,这是实话,因为RTX在视口下借助OptiX加速的确可以做到秒出。在整个材质和光影的调整过程中,我非常享受这一过程带给我的流畅的反应速度和超快速渲染成像,原来需要数个甚至数十个工作日才能调整完成的材质效果,现在借助RTX显卡变得非常有效率,40多个复杂的节点材质一个半工作日全部完成。这种愉快的感受实在没法用文字说明,当你真正使用时你会实实在在的切身感受到,RTX的OptiX所带来前所未有的效率。
这里提供了2000万面数下的视口操作录屏,视口移动旋转豪无压力,渲染成像超级快速。
视频录制会出现卡顿,操作本身没有卡顿!请看提供视频:
[ 凯普强殖巨人装甲胸像Cycles视口OptiX操作录屏.MP4 ]
https://www.bilibili.com/video/BV1f54y1S7xE?p=1
接下来再来看看成品级图像的测试!
*Cycles成品级渲染测试:四个渲染尺寸:3K 5K 8K 10K
注意:四个渲染尺寸不是只渲染一次, 10K由于时间关系只渲染了两次,8K渲染了5次提供两次不同采样的结果,至于5K和3K RTX表示小意思,哈哈。每次测试的时间相差不大。
采用块分布式渲染,块大小:512X512,开启OptiX 后期降噪:Color+Albedo+Normal
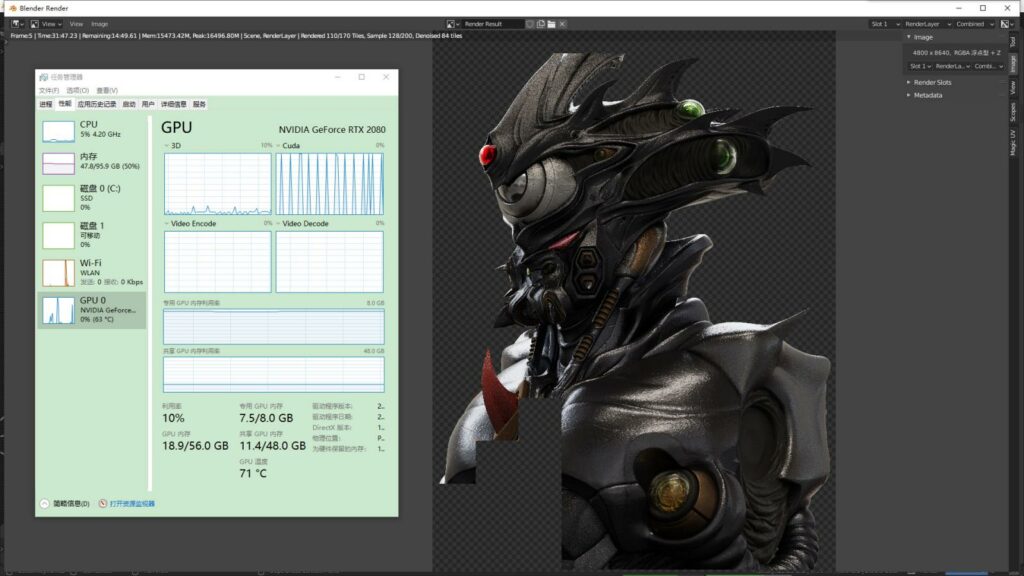
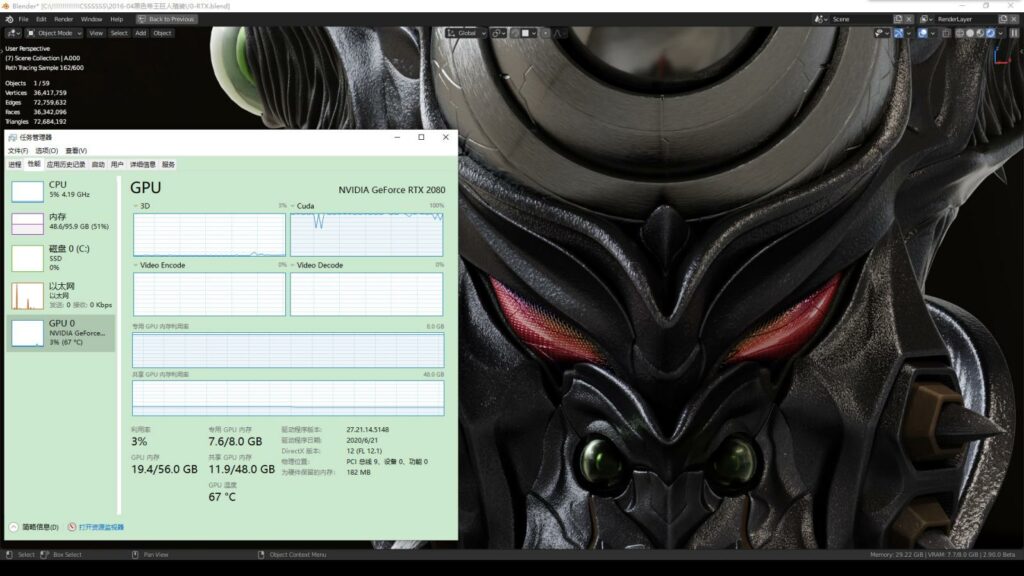
8K渲染过程截图,GPU显存使用7.5GB,外部内存调用11GB左右。
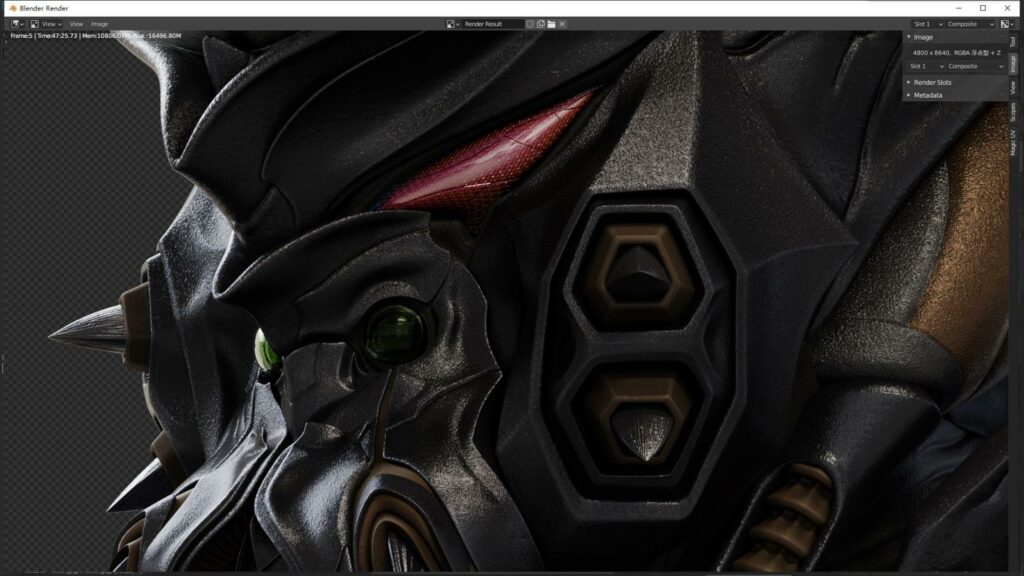
8K成图局部,1:1,虽然只有200采样,凭借强大的OptiX后期降噪技术,画面品质很赞。
RTX2080 OptiX加速下的渲染成绩:
*注:8K大图共分为170块,渲染过程中出现了显卡过热降频的情况,显卡最高温度观察到是74度,如果没有降频,渲染时间应该还可以再少。
采样数值的不同:我的测试不只是为了速度,我还要保证画面的质量,所以不同尺寸会有不同的采样,是保证速度和质量的平衡参数。
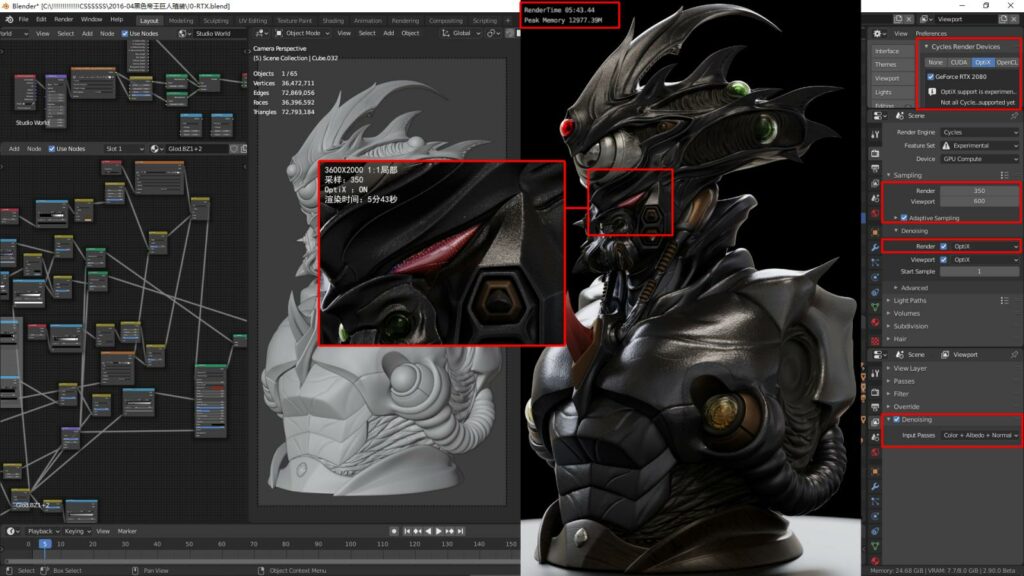
首先来看一下没有开启OptiX加速的CUDA渲染成图的时间:图片尺寸:3600X2000 采样:350 渲染时间:17分13秒
使用了Blender自带的NLM降噪,暗部噪点还是很明显。Intel的Open Image Denoise会让细节损失太多所以这里没有使用。
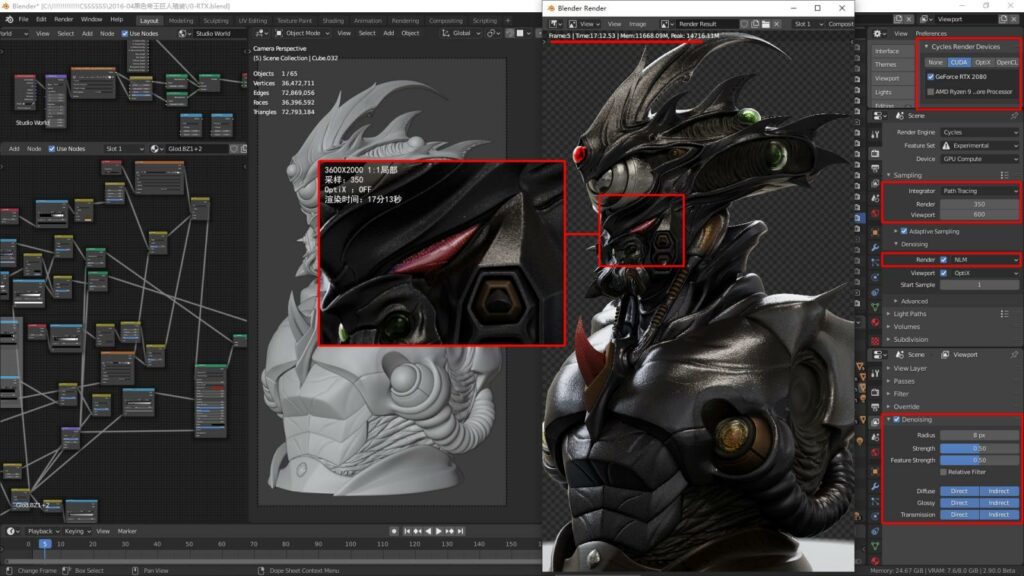
再来看看开启OptiX加速后的渲染成绩:
图片尺寸:3600X2000 采样:350 渲染时间:5分43秒
其他渲染尺寸和时间:
图片尺寸:5040X2800 采样:300 渲染时间:10分39秒
图片尺寸:8640X4800 采样:150 渲染时间:29分51秒
图片尺寸:8640X4800 采样:200 渲染时间:47分25秒
再来看看更极端的尺寸,10800X6000
200采样,264个分布块,渲染时间:1小时42分09秒
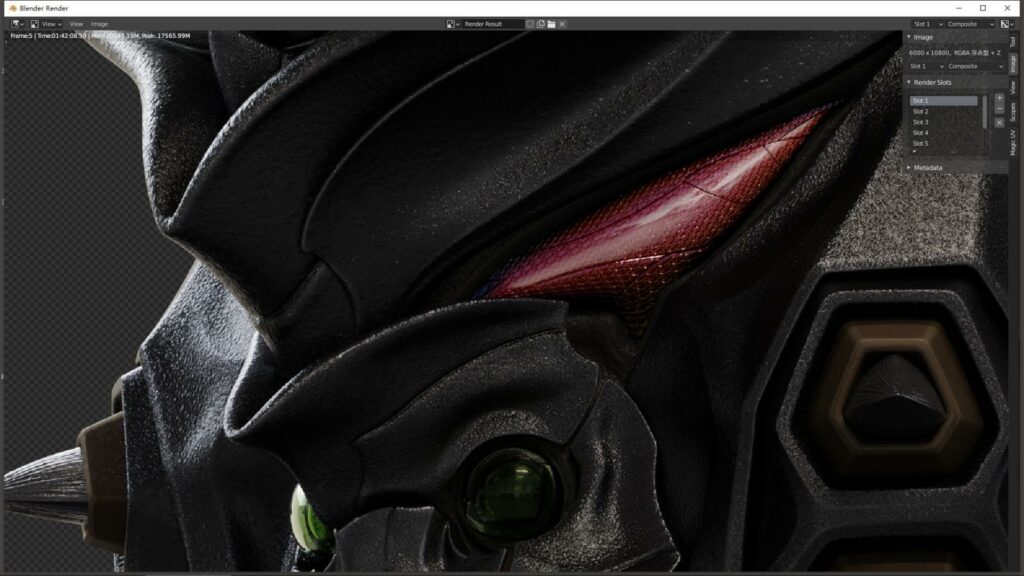
1万像素,1:1局部截图
Cycles成图渲染总结:
说实话个人觉得渲染速度非常让我惊叹,4年前我渲染这张图5K大小,运用了两颗2.8G 40线程的志强CPU的工作站花费了2小时40分钟,采样开到1000才完成渲染,效果还没有现在这个好。而现在运用RTX后5K的图10分钟就可以完成,8K的图居然可以在不到1小时完成高品质的渲染。10K的图也能在两小时内完成渲染。在几年前实在不敢想象这样的速度会在一块显卡上实现。现在RTX GPU强大硬件和OptiX加速让渲染成图速度有了真正质的飞跃!
—————————————————————————————————————————–
测试作品-双生头骨(以下测试结果是极端条件数据!)
渲染器:Blender2.9beta EEVEE
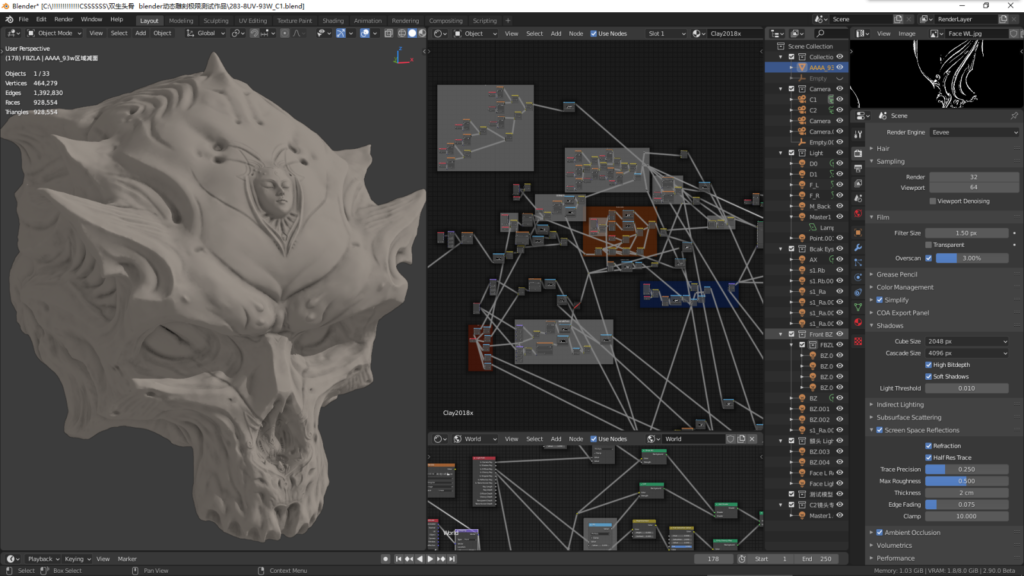
注意:双生头骨的测试只使用EEVEE实时引擎,因为300万的模型对有RTX的OptiX加速技术的Cycles完全是小菜。
测试文件介绍:
Blender动态雕刻单体极限面数测试作品,整个头骨由一个整体部件雕刻完成,没有任何部件组合,单体动态三角面300万(3095210面数)(还有一个是精简版面数在93万左右)。整个头骨拥有3个细节纬度,分别是:
a头骨整体两面骷髅面和鸟骨面,b额前慈女面和头顶龟背冢,c骷髅面的鼻骨世界。
双生头骨是一个完全的动态雕刻模型,没有经过任何重托布的操作,所以你应该明白对它展UV将意味者一张UV通道需要超过4~5个小时的时间。
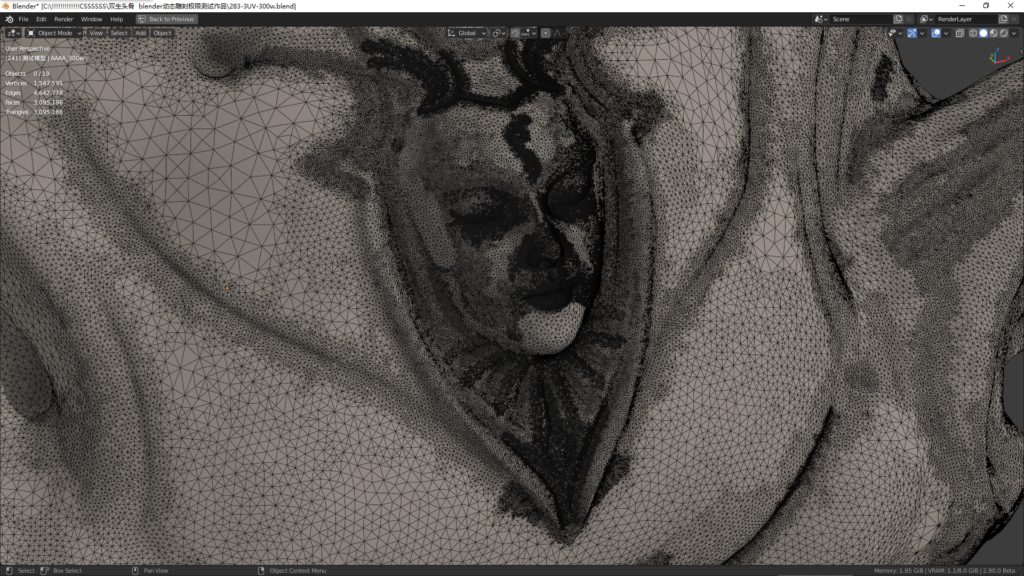
首先测试300万动雕的头骨模型,灯光20个,3套UVmap通道,开启视口降噪,EEVEE的shadows的都调到最高4K。
材质介绍:14张贴图,主要贴图尺寸:12K~3K,通过复杂的材质节点结构融合成一个材质。
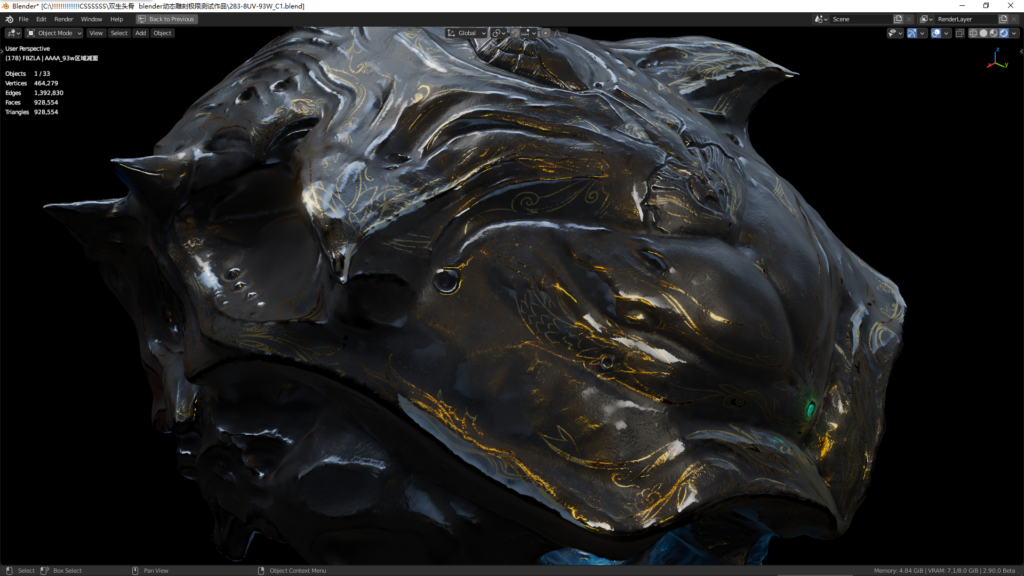
在视口下转动和拖到视图有明显的卡顿(为什么会卡顿呢?因为我开启了EEVEE的软阴影,当把软阴影关闭后一切变得顺滑流畅),但是编辑材质和调整灯光完全不受影响,实时显示反应速度很快,视图任意放大,最大化切换略微卡顿,但完全不影响我的操作。
好!我们换93万的更复杂的材质完整版来看看。
93万动雕的头骨模型,灯光27个,8套UVmap通道,开启视口降噪,EEVEE的shadows的都调到最高4K。
材质介绍:34张贴图,主要贴图尺寸:12K~3K,通过超复杂的材质节点结构融合成一个材质。
虽然面数比300万少了不少,但是93万的头骨模型拥有比300万头骨更复杂的材质节点,有8个UV通道组成超复杂的材质结构。
其中花纹设计绘制全部在Blender中完成。
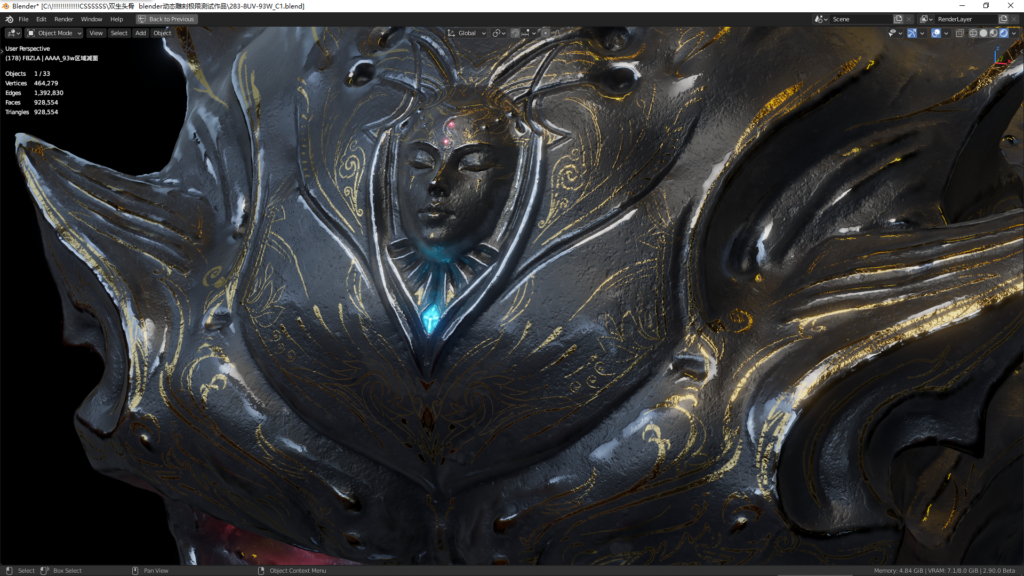
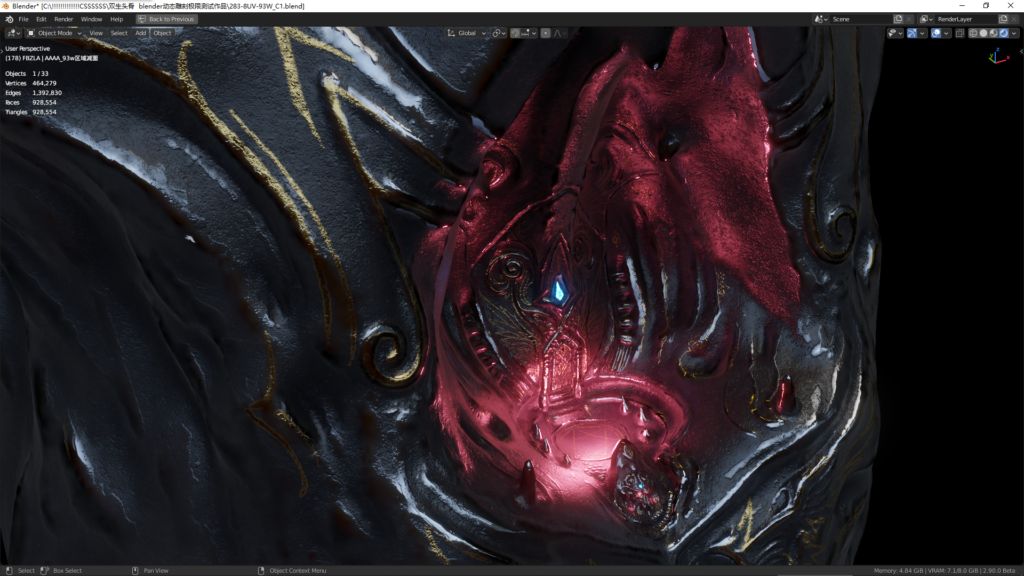
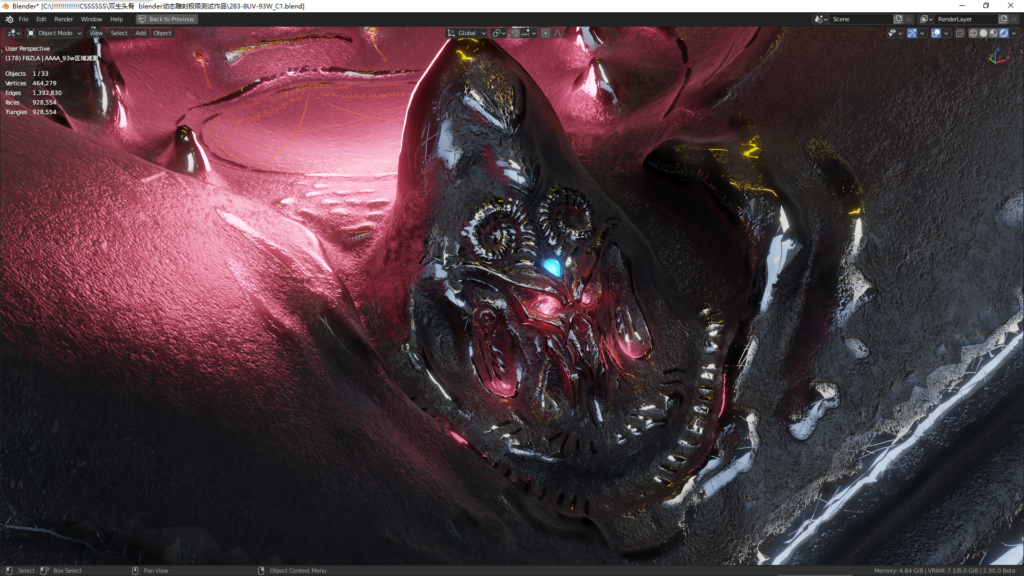

93万头骨在视口下转动和拖到视图只有稍许的卡顿(开启了EEVEE的软阴影),编辑材质和调整灯光完全不受影响,实时显示反应速度超~~~~~快。材质中所有细节在不到1秒的时间内完美呈现,视图任意放大,最大化切换都毫无压力。
EEVEE实时视口测试总结:
EEVEE借助强大的RTX显卡,得以把超复杂的模型和材质完美快速的实时渲染出来,这对于游戏美术艺术家而言是一个强劲的助力,
可以毫无压力的在实时显示的情况下,对复杂的模型和复杂的PBR材质进行快速的调整、编辑。而对于一个次世代模型而言,RTX显卡更是能轻松应对各种复杂的场景、角色、动画和特效的预览。这些你可能都会想到,但是否想过,未来的电影级别动画制作,在Blender上借助这样强劲的RTX显卡将变成更加有趣且非常完整视觉化的事情。
我们来看看借助RTX显卡EEVEE成图的渲染能力。
EEVEE的成图渲染:

2400X2400 全合成通道 64采样 渲染时间:1分29秒(截图画面为1:1局部)

8400X8400 全合成通道 64采样 渲染时间:14分56秒(截图画面为1:1局部,开启景深模糊-部分画面有模糊)
好EEVEE的专门测试就到这里,最后再测试一个带有Blender毛发的案例。
祈祷女孩素模版
这是一个商业实战的案例,只是彩色版本还在制作中,所以只好拿素模版来做测试了。
交稿时间太紧,只能使用减过面的雕刻模型来测试了。
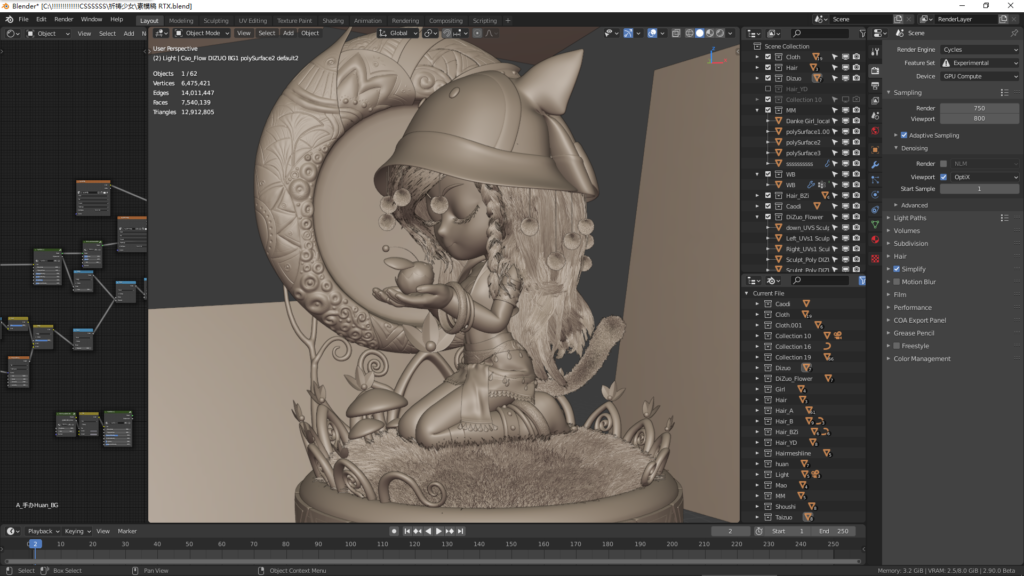
测试文件介绍:
主体55个对象(其余是灯光和辅助物体和摄像机),共750万左右的面数
33个材质,41张贴图,最大8K
9个毛发粒子总共约64万根毛发:
(Blender没有对自己毛发数量的统计功能,以下毛发数量是大概的计算得到的,但相差也不会太大)
尾巴毛发数量:9万根左右
草地毛发数量:3万7千根左右
头发毛发数量:19万根左右
辫子毛发数量:2万根左右
帽子绒球毛发数量:30万左右
64万根毛发我都在视口中全部开启,我们先来看看Cycles视口渲染的能力,OptiX开启!
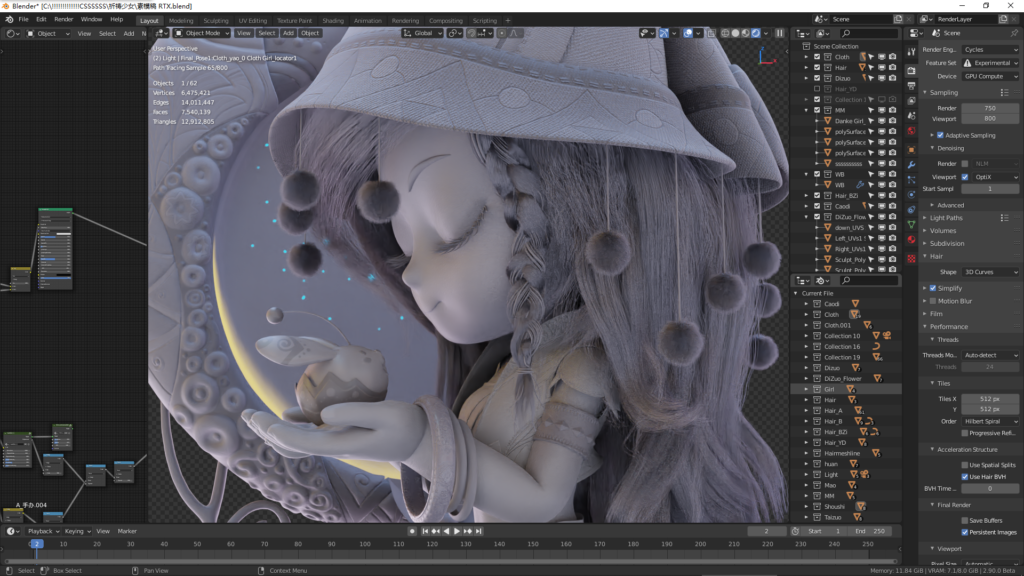



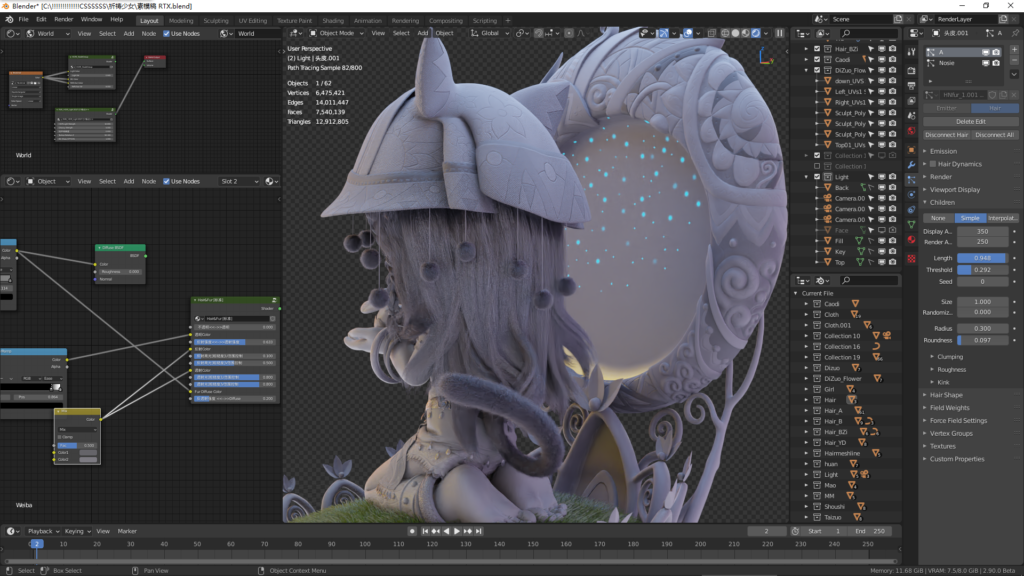
视口在物体离得很近时旋转和拖动有轻微卡顿,还有毛发多的地方也会有卡顿,2秒成像,4秒凹凸细节清晰呈现,11秒毛发细节清晰可见。材质编辑和灯光调整都非常顺畅,反应速度,几乎是所见即所得,视口最大化切换也没有任何压力,在这种速度下调整材质真是一种享受,哈哈。
操作流畅感可以看我提供的视频录像,录像时出现的卡顿,不是视口卡顿。
[ 祈祷女孩素模稿-CyclesOptiX视口操作录屏.MP4 ]
https://www.bilibili.com/video/BV1f54y1S7xE?p=2
我们再来看看64万根毛发在EEVEE中会如何?
注:EEVEE不支持材质性的Mesh光体照明,所以这里场景只有两盏主光源和HDR在起作用,所以视觉效果差一些。
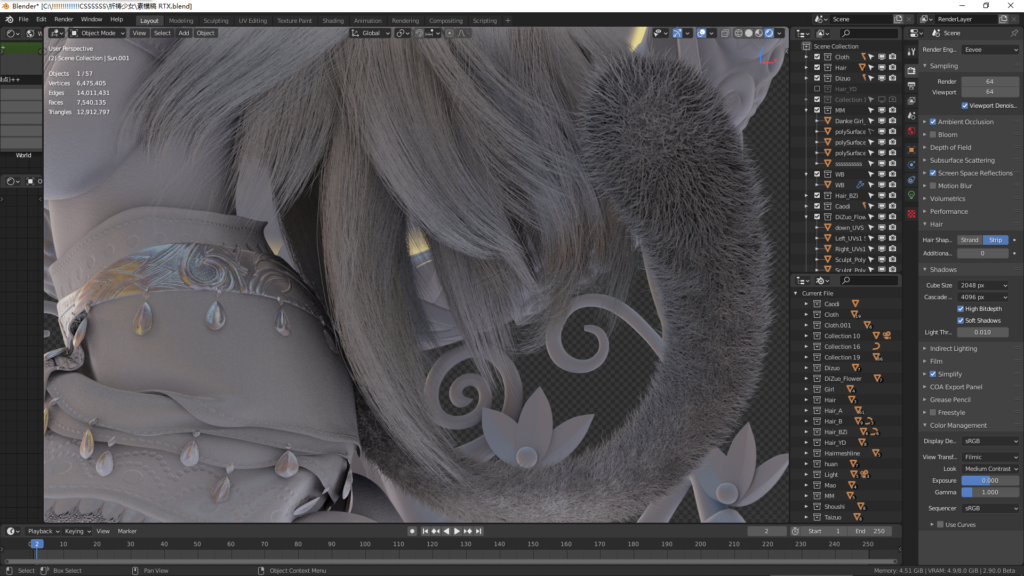

开启了软阴影,视口旋转拖拽毫无压力,编辑材质和灯光也是立刻反馈,毛发呈现细腻,凹凸质感也非常清晰。
操作流畅感可以看我提供的视频录像,为了录像时减少卡顿,减少了采样,录像时出现卡顿,不是视口卡顿。
[ 祈祷女孩素模稿-EEVEE视口操作录屏.MP4 ]
https://www.bilibili.com/video/BV1f54y1S7xE?p=3
好啦,给的测试时间不多,只能测试这些内容,Blender这两年突飞猛进的发展,使它在某些环节变得非常优秀,而RTX
2080对于现在的Blender2.9的优化支持可谓是如虎添翼,本来就非常方便的视口运用,加上OptiX加速技术让整个工作流程效率都有了巨大的提升。对于游戏,建模,材质编辑,动画特效和渲染这些艺术工作者有着非凡的意义!
从上述分享的测试成绩来说,个人觉得OptiX加速技术给显卡带来了一次3D图像速度渲染的飞跃,虽然CUDA已经很快了,但是可以为拥有OptiX API支持的RTX20系列GPU带来更加强劲的速度和性能,而这种提升不是一点点,而是一个质量级,它彻底改变了3D艺术创作中最耗时耗神的材质调试和成图渲染环节,让3D艺术家从折磨般的等待中解放出来,带着愉快和享受的心情沉浸在奇妙的创作中,在超精致的模型上流畅雕刻,实时编辑材质,灯光和动画,这一切在几年前是无法想象,而现在NVIDIA为我们带来一个很赞方向,而我相信这只是开始。


最近纠结3080与6900xt,毕竟黄牛党的3080非公已经到了7400左右。希望看到6900xt或者6800xt的测试。
为什么我的n卡2080ti经常闪退呢,系统日志提示OpenGL错误导致关闭窗口,显卡驱动和win10操作系统都完全重新安装的,依然不行,显卡都换了2块了,希望有大佬高手帮忙指点指点,不然只能一直用a卡了
社区也有类似配置的机器,但是并没有出现你所说的问题。你是只用Blender吗?还是有其他的软件混合使用?
啊,我莫得技术,莫得感情。
这渲染这模型,酸了